Multibank Group is a one the largest financial derivatives companies globally with 20+ offices and a paid-up capital of $322 million. The group with various member companies is active in areas from asset management to brokerage with a leading trading platform.
One of the groups entities was planning to migrate a mission critical application to AWS handling real time financial transactions. The migration was conditional on achieving a highly redundant architecture with cluster failover of less than 5 seconds. The application can’t handle an active-active architecture hence an active-passive architecture.
Active/Passive clustering has always been a very well-known
strategy cloud experts have used to provide a fully redundant
architecture where a secondary node is brought online when a
primary node fails to respond. Nevertheless, setting up an
Active/Passive cluster really depends on the client’s needs
based on a specific scenario that meets their availability
requirements.
Although Amazon Route53 can be configured for an
active-passive failover through health checks and failover
routing policies, the minimum failover time for Route53 is
around 70 seconds computed as follows:
Failover = TTL + (Interval * Threshold)
If you have a TTL of 60 seconds, checks at 10 second
intervals, and a threshold of 1, the failover process will
take 70 seconds:
Failover = 60 + (10 * 1)
Application load balancer (ALB) target groups health check
wasn’t a valid solution for this scenario since the minimum
period between each check is 5 seconds and at least 2
successive failures are needed to mark an instance as
unhealthy, which lead us to 10 seconds at best.
Zero&One knows exactly what innovation stands for in the world
of cloud, and that’s where our team put all the skills and
expertise needed to come up with a tailor-made solution within
a short period of time:
• Application Load Balancer • Two target groups, one that is
active and another that is passive, with weighted target group
routing that allows us to control the distribution of traffic
to the application. • Lambda functions: • Check current Load
Balancer weight configuration • Conduct a health check on the
active server • Flip the weight of target groups upon failover
• Step functions to orchestrate the whole Lambdas
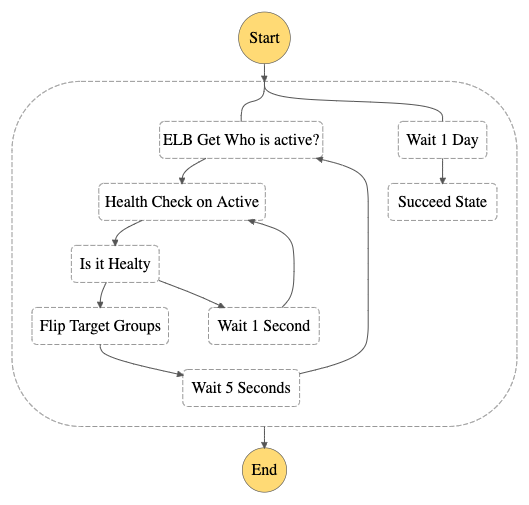
The above diagram shows the flow of our Lambdas and how we
were able to achieve a 3-second failover time.
Even though this solution achieved a less than 5-second
failover time, Lambda requests and step function states
required around 86,400 Lambda invokes and more than 250,000
states daily. This led us to use CloudWatch events to restart
Step Function executions every 30 minutes in order to avoid
reaching the maximum number of registered state machines,
which is 10,000.
Fortunately, our team was able to overcome this hindrance by
leveraging Step Function Activity instead of Lambda, which
consists of a program code that waits for an operator to
perform an action or to provide input. The next step was for
us to write a simple code that sends heartbeats using the
SendTaskHeartbeat API action, running it on each of the EC2
instances. Once the Step Function Activity stops receiving
heart beats from the active server, it will automatically
failover to the standby target group.
Step Function Activities enabled us to:
• Reduce the number of Lambda invocations to get the health of
the active instance behind a target group. • Reduce the number
of Step Function State Machines. • Use Activity Heartbeat to
confirm the health of the server. • Use Activity Heartbeat
timeout to allow a grace period on health check, so we don’t
fake flip target groups and to correctly flip if a server is
completely down. • Use State Retry and Error Handling to
confirm we do flip the target group and nominate the passive
server into active.
Note:
Step Function maximum time is 1 year, so we prepared a
schedule to rerun it on daily basis.
Client obsession is at the center of Zero&One. We made sure to leverage our expertise and skills to natively build a custom solution on AWS to meet and exceed Multibanks expectations. We were able to ensure that the customer does not suffer revenue loss or loss of reputation in the case of an IT disruption by enabling them with a highly redundant architecture with failover clustering of less than a 5-second while maintaining a cost effective, clean and future proof solution that does not reach the boundary of any AWS service.


