Nowadays, most offices are monitored by CCTV cameras. Have you ever wondered if there is a way to use the footage for fun purposes other than security?
In this blog I will go through a solution that was part of a Lunch and Learn project at my company. It analyzes the CCTV footage using Amazon Rekognition and stores the information on S3 to be displayed on Amazon Quicksight. The data includes the total number of employees detected, emotions, gender, age range, etc...
The solution architecture is shown in the following picture:
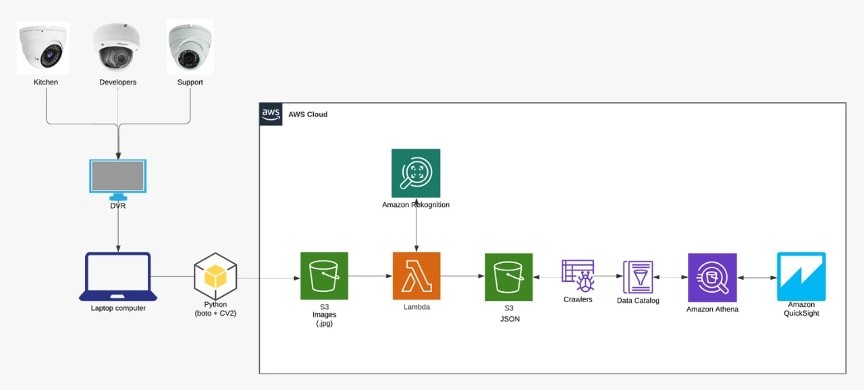
Three installed cameras were used: one showing the kitchen, the second showing the developers team, and the third one showing the support team. The data from all three cameras were taken on a laptop computer through the DVR connected to the cameras.
The first thing you need to do is to extract frames from the CCTV video using the CV2 python library and upload the images to an S3 bucket using Boto3, a python AWS SDK (Software Development Kit).
import logging
from datetime import timedelta, datetime
import cv2
import numpy as np
import os
import boto3
from botocore.exceptions import ClientError
# Duration between frames
MINUTES_PER_FRAME = 1
# Number of frames per second
SAVING_FRAMES_PER_SECOND = 1/(60*MINUTES_PER_FRAME)
def format_filename(filename):
filename = str(filename)
filenameList = filename.split("_")
date_unformatted = filenameList[3]
format_data = "%Y%m%d%H%M%S"
return datetime.strptime(date_unformatted, format_data), filenameList
def format_timedelta(td, filename):
"""Utility function to format timedelta objects in a cool way (e.g 00:00:20.05)
omitting microseconds and retaining milliseconds"""
date, filenameList = format_filename(filename)
name = str(date + td)
return f"{filenameList[0]}_{filenameList[1]}_{filenameList[2]}_{name}".replace(" ", "_").replace(":","-")
def get_saving_frames_durations(cap, saving_fps):
"""A function that returns the list of durations where to save the frames"""
s = []
# get the clip duration by dividing number of frames by the number of frames per second
clip_duration = cap.get(cv2.CAP_PROP_FRAME_COUNT) / cap.get(cv2.CAP_PROP_FPS)
# use np.arange() to make floating-point steps
for i in np.arange(0, clip_duration, 1 / saving_fps):
s.append(i)
return s
def upload_file(file_name, bucket, object_name=None):
"""Upload a file to an S3 bucket"""
# If S3 object_name was not specified, use file_name
if object_name is None:
object_name = os.path.basename(file_name)
# Upload the file
s3_client = boto3.client('s3')
try:
response = s3_client.upload_file(file_name, bucket, object_name)
except ClientError as e:
logging.error(e)
return False
return object_name
def extractFrames(video_file):
filepath, filename = os.path.split(video_file)
# temporary path to store images before upload to s3
path = "{local output temporary path to store images}" + filename.split("_")[1]
pathDate = path + "/" + str(format_filename(filename)[0]).replace(" ", "_").replace(":", "-").split("_")[0]
# store uploaded frames in Output-Frames folder
pathS3 = "Output-Frames/" + filename.split("_")[1]
pathDateS3 = pathS3 + "/" + str(format_filename(filename)[0]).replace(" ", "_").replace(":", "-").split("_")[0]
# make a folder by the name of the video file
if not os.path.isdir(path):
os.mkdir(path)
if not os.path.isdir(pathDate):
os.mkdir(pathDate)
# read the video file
cap = cv2.VideoCapture(video_file)
# get the FPS of the video
fps = cap.get(cv2.CAP_PROP_FPS)
# if the SAVING_FRAMES_PER_SECOND is above video FPS, then set it to FPS (as maximum)
saving_frames_per_second = min(fps, SAVING_FRAMES_PER_SECOND)
# get the list of duration spots to save
saving_frames_durations = get_saving_frames_durations(cap, saving_frames_per_second)
# start the loop
count = 0
while True:
is_read, frame = cap.read()
if not is_read:
# break out of the loop if there are no frames to read
break
# get the duration by dividing the frame count by the FPS
frame_duration = count / fps
try:
# get the earliest duration to save
closest_duration = saving_frames_durations[0]
except IndexError:
# the list is empty, all duration frames were saved
break
if frame_duration >= closest_duration:
# if closest duration is less than or equals the frame duration,
# then save the frame
frame_duration_formatted = format_timedelta(timedelta(seconds=frame_duration), filename)
cv2.imwrite(os.path.join(pathDate, f"{frame_duration_formatted}.jpg"), frame)
filenameOS = pathDate + f"/{frame_duration_formatted}.jpg"
filenameS3 = pathDateS3 + f"/{frame_duration_formatted}.jpg"
# upload file to s3
upload_file(filenameOS, '{s3-bucket-name}', filenameS3)
# remove temp file after upload
os.remove(filenameOS)
# drop the duration spot from the list, since this duration spot is already saved
print()
try:
saving_frames_durations.pop(0)
except IndexError:
pass
# increment the frame count
count += 1
def main(folder_path):
onlyfiles = [f for f in listdir(folder_path) if isfile(join(folder_path, f))]
print(str(onlyfiles))
# loops on all files in folder to extract frames from .mp4 files
for video in onlyfiles:
if video.split(".")[1] == "mp4":
path = os.path.join(folder_path, video)
print(path)
# extract frames function from extractFrames.py
extractFrames(path)
if __name__ == "__main__":
video_file = sys.argv[1]
main(video_file)
After the images are uploaded to an S3 bucket as jpg images, a lambda function is triggered with each image upload. It analyzes the images using Amazon Rekognition, a service that takes an image and performs highly accurate facial analysis, face comparison and face search capabilities.The resulting data is stored in an S3 bucket as JSON format.
Below, I will be detailing the lambda function:
I will be using two types of Amazon Rekognition APIs:
detect_faces: detects the faces and returns face details like the emotions, gender, and age.
def detect_faces(photo, bucket, baseName, json_directory):
"""
Detects faces in the image.
:return: The list of faces found in the image.
"""
rekognition=boto3.client('rekognition')
s3=boto3.client('s3')
try:
response = rekognition.detect_faces(Image={'S3Object': {'Bucket': bucket, 'Name': photo}}, Attributes=['ALL'])
channel, date_time = name_selector(photo)
faceDetails = response['FaceDetails']
for index, faceDetail in enumerate(faceDetails):
selected_details = face_details_selector(faceDetail, index, date_time, baseName)
json_file_name = json_directory + selected_details['id'] + '.json'
jsonObject = json.dumps(selected_details)
upload_json_s3(json_fileName = json_file_name, json_data = jsonObject, s3_bucketName = bucket)
except ClientError:
logger.info("Couldn't detect labels in %s.", photo)
raise
faceDetails_selector.py : used to select required details from detect face response
def face_details_selector(faceDetail, index, date_time, baseName):
id = baseName + "_" + str(index)
faceObject = {
"id": id,
"date_time": date_time,
}
for detailName, detail in faceDetail.items():
if detailName == "Smile":
faceObject[detailName] = detail['Value']
elif detailName == "Gender":
faceObject[detailName] = detail['Value']
elif detailName == "Age":
faceObject[detailName] = detail['Value']
elif detailName == "Emotions":
for emotion in detail:
faceObject[emotion['Type']] = emotion['Confidence']
return faceObject
detect_labels: detects all objects in an image and we can select only the humans detected. This will be used to detect the number of people at a moment in time.
def detect_labels(photo, bucket, json_fileName):
rekognition=boto3.client('rekognition')
s3=boto3.client('s3')
try:
response = rekognition.detect_labels(Image={'S3Object': {'Bucket': bucket, 'Name': photo}})
channel, date_time = name_selector(photo)
detected_persons = {
"persons_detected": 0,
"date_time": date_time,
}
labels = response["Labels"]
for label in labels:
if label["Name"] == "Person" or label["Name"] == "Human":
number_of_people = len(label["Instances"])
detected_persons["persons_detected"] = detected_persons["persons_detected"] + number_of_people
except ClientError:
logger.info("Couldn't detect labels in %s.", photo)
raise
else:
jsonObject = json.dumps(detected_persons)
upload_json_s3(json_fileName = json_fileName, json_data = jsonObject, s3_bucketName = bucket)
upload_to_s3.py : uploads json to s3
import boto3
def upload_json_s3(json_fileName, json_data, s3_bucketName):
s3 = boto3.resource('s3')
s3object = s3.Object(s3_bucketName, f'{json_fileName}')
s3object.put(
Body=(bytes(json_data.encode('UTF-8')))
)
name_selector.py : small utility function split the file name into its components
def name_selector(raw_name):
sections = raw_name.split("_")
channel = sections[1]
date = sections[3]
time = sections[4].replace("-",":").split(".")[0]
date_time = f"{date} {time}"
return channel, date_time
lambda_handler.py : the lambda function that is triggered when a new image is uploaded to S3
import boto3
import json
from rekognize import detect_labels, detect_faces
from upload_to_s3 import upload_json_s3
from channel_selector import channel_selector
def lambda_handler(event, context):
image_file_name = event['Records'][0]['s3']['object']['key']
image_s3_bucket = event['Records'][0]['s3']['bucket']['name']
image_file_name_splitted = image_file_name.split('/')
image_base_name = image_file_name_splitted[3].split('.')[0]
channel = channel_selector(image_file_name_splitted[1])
date = image_file_name_splitted[2]
json_base_name = image_base_name + ".json"
json_file_name = f"Output-Json/LabelsDetected/channel={channel}/date={date}/{json_base_name}"
detect_labels(image_file_name, image_s3_bucket, json_file_name)
json_directory_faces = f"Output-Json/FacesDetected/channel={channel}/date={date}/"
detect_faces(image_file_name, image_s3_bucket, image_base_name, json_directory_faces)
return {
'statusCode': 200,
'body': json.dumps(event)
}
After running the script on all the videos you want to analyze, you will have the data
stored as JSON partitioned by channel and date on S3.
Optionally, to visualize the data, you can create Data Catalogs by running an AWS Glue
crawler on the data stored on S3. Afterward, using Amazon Quicksight, you can directly
fetch the data from the catalogs to create datasets and display them on dynamic
dashboards.
Below are some of the graphs I took from quicksight:
-
The average number of people found per hour: You can see how the developers and support channels detect less people at noon but the kitchen channel increases
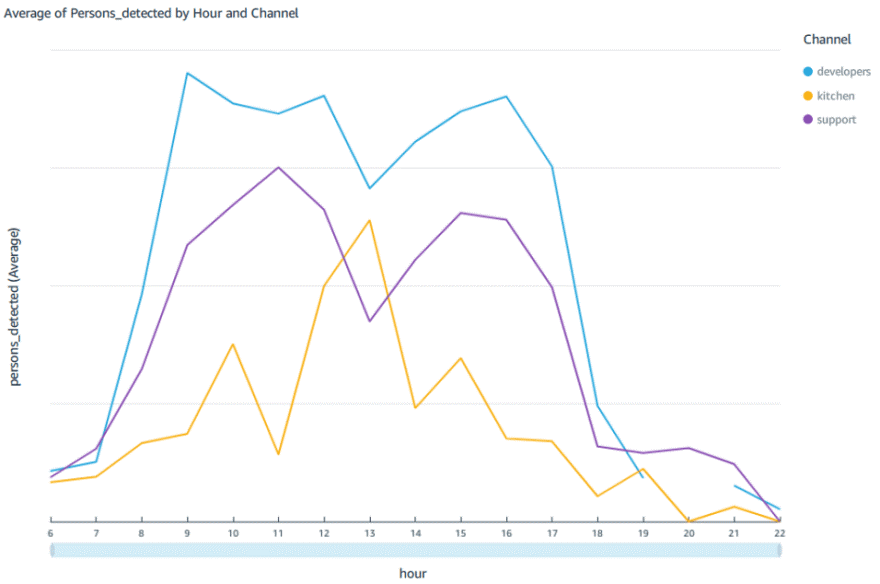
-
The average happy faces detected per day (Monday - Friday): We can say that Friday can be officially changed to Fri-YAY! (Jun 6 being Monday and Jun 10 Friday)
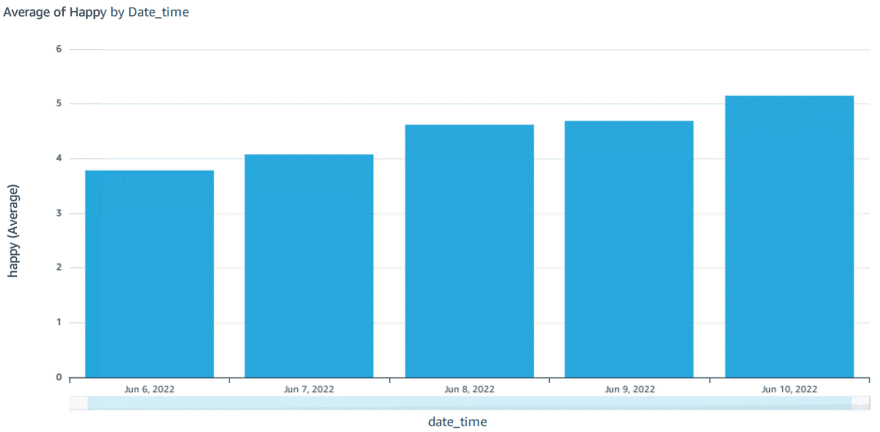
-
Percentage of happy Faces detected by channel: And of course the kitchen is the happiest place in the office
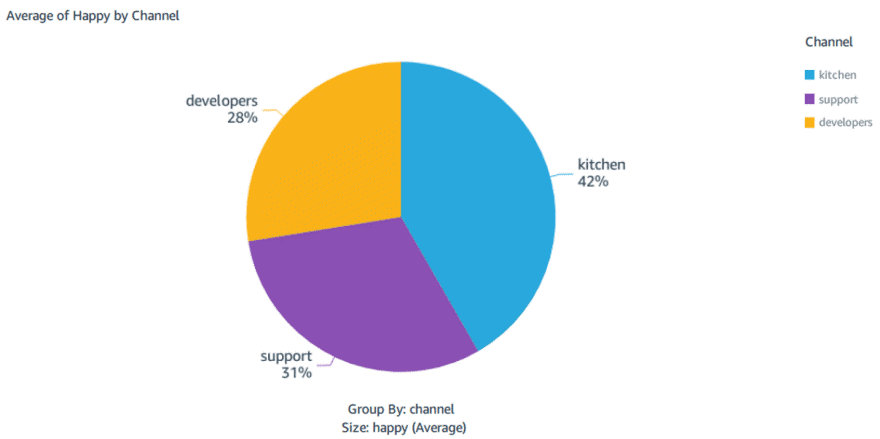
Summing it up, the sky is your limit! You can now start your journey in harvesting the power of AI and building fun new projects with Amazon Rekognition.



